After yesterdays work – to correct the collision detection – today I wanted to do something different and started a first “improvement” round.
The results as an Intro:
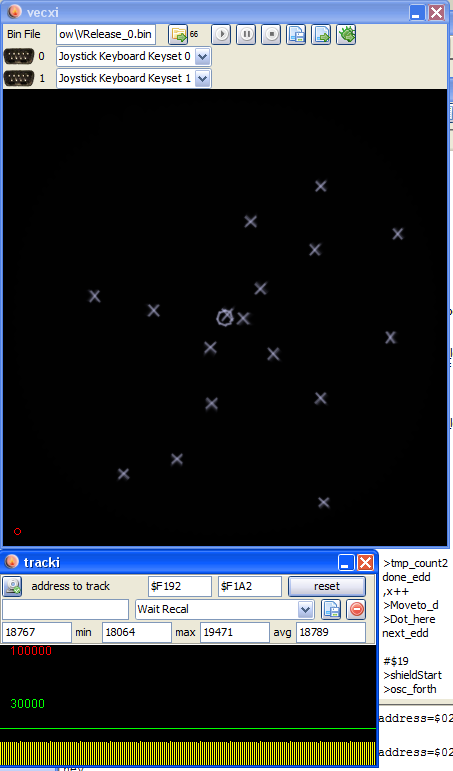
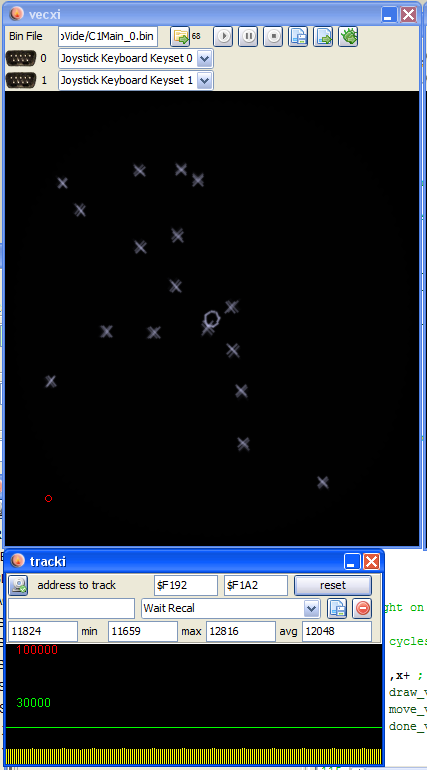
One image pre optimization (~ 19000 cycles) and post optimization (12000 cycles), same amount of enemies.
Here a list of things I changed (took about 1h):
Structure and user stack
I changed the object structure from:
struct ObjectStruct ds BEHAVIOUR,2 ds TYPE,1 ; enemy type ds SCALE,1 ; scale to position the object ds ANGLE,2 ; if angle base, angle in degree *2 ds Y_POS,1 ; current position ds X_POS,1 ds CURRENT_LIST,2 ; current list vectorlist ds DRAW_ROUTINE,2 ; jmp to current draw routine ds PREVIOUS_OBJECT,2 ; positive = start of list ds NEXT_OBJECT,2 ; positive = end of list ds filler, 5 end struct
To:
struct ObjectStruct ds Y_POS,1 ; current position ds X_POS,1 ds CURRENT_LIST,2 ; current list vectorlist ds DDRA,1 ds SCALE,1 ; scale to position the object ds BEHAVIOUR,2 ds TYPE,1 ; enemy type ds ANGLE,2 ; if angle base, angle in degree *2 ds PREVIOUS_OBJECT,2 ; positive = start of list ds NEXT_OBJECT,2 ; positive = end of list ds filler, 5 end struct
This as mentioned befor allows better usage of the user stack (you will see shortly what I mean).
The before mentioned
bsr do_objects
in the main loop was removed and replaced with:
ldu list_objects_head pulu d,x,y,pc ; (D = y,x, X = vectorlist, Y = DDRA+Scale)
As before – this code automatically loops thru all objects. The “empty” list object was replaced with data that points as “pc” to the entry of the main function – so the main loop automatically resumes.
The “pulu” now pulls the register d,x,y and pc.
D – contains the position of the object
X – contains a pointer to the vectorlist, that must be drawn
Y – contains the scale I use for drawing (but since Y is 16 bit instead of 8, I also load $ff and poke the complete Y register to VIA ddra – which sets the scale)
PC – logically is still the behaviour routine
Anyway – loading all that data and jumping to my behaviour routine takes 13 cycles – which is pretty damn fast.
Object behaviour
The only object I optimized yet is the X object.
Old source:
xBehaviour dec SCALE+u_offset1,u bne base_not_reached PLAY_SFX Gotcha_Sound bra removeObject base_not_reached lda SCALE+u_offset1,u sta VIA_t1_cnt_lo ; to timer t1 (lo) JSR Intensity_5F ; Sets the intensity of the ldd Y_POS+u_offset1,u jsr Moveto_d lda #6 sta VIA_t1_cnt_lo ; to timer t1 (lo= ldx CURRENT_LIST+u_offset1,u jsr [DRAW_ROUTINE+u_offset1,u] _ZERO_VECTOR_BEAM ldu NEXT_OBJECT+u_offset1,u pulu pc
And the new source:
xBehaviour ; do the scaling sty VIA_DDR_a ; also stores to scale :-() VIA_t1_cnt_lo ; to timer t1 (lo) ; start the move to MY_MOVE_TO_D_START ; following calcs can be done within that move lda SCALE+u_offset1,u ; load current scale to a - for later calcs dec TICK_COUNTER+u_offset1, u ; see if we need calc at all, compare tick counter with below zero bpl no_scale_update_xb ; if not, scale will not be updated ldb X_add_delay ; otherwise reset the delay counter for scale update (this is global now, should I use that from the structure?) stb TICK_COUNTER+u_offset1, u ; store it suba SPEED_COUNTER+u_offset1, u ; and actually descrease the scale with the "decrease" value bcc base_not_reached ; if the decreas generated an overflow - than we reached the base (scale below zero) ; if we reached the base - ; a) moveto was SMALL - finished anyway ; b) not interested in move - nothing will be drawn anymore! ; MY_MOVE_TO_B_END jmp gameOver ; if base was hit -> game over base_not_reached: sta SCALE+u_offset1,u ; store the calculated scale (used next round) no_scale_update_xb: ldu NEXT_OBJECT+u_offset1,u ; preload next user stack lda #$5f ; intensity MY_MOVE_TO_B_END ; end a move to _INTENSITY_A lda #6 sta VIA_t1_cnt_lo ; to timer t1 (lo= jsr myDraw_VL_mode _ZERO_VECTOR_BEAM pulu d,x,y,pc ; (D = y,x, X = vectorlist, Y = DDRA+Scale)
As you see – I actually do MORE than before (checking whether to decrement scale and using a decrement value instead of just a dec).
The new bevaviour does:
a) use the values initialized by the user stack pulu
b) uses a macro for move to (actually split macro), the first part initialized the move – but does not wait for the move to finish
c) than I can do some stuff that does not influence the move, but cost a few cycles
d) finish the moveTo by a seperate macro, which basically waits for the interrupt flag of T1
e) set the intensity with a macro instead a subroutine (haven’t gotten any different intensities yet – so for now this is overkill)
f) use a draw routine directly, instead from the object structure, the behaviour rotuine is specialized already…
g) the draw routine is hand written and not the BIOS routine anymore
h) initialize the next object by pulling form the newly initialized U pointer (while “in” movetoD)
Everything together did not take more than an hour – but the result is, that the whole program uses about 30% less cycles.
(There will be more optimizations later on – but these is still the basic prototype – where I try things out).
Regards
Malban